#48 - Why LLMs will never replace ML models
A few months back a data scientist at Stripe wrote a Linkedin post about how they trained a “payments foundation model” by using LLMs.
They described how it outperformed their “traditional” ML model and provided the table below as reference:
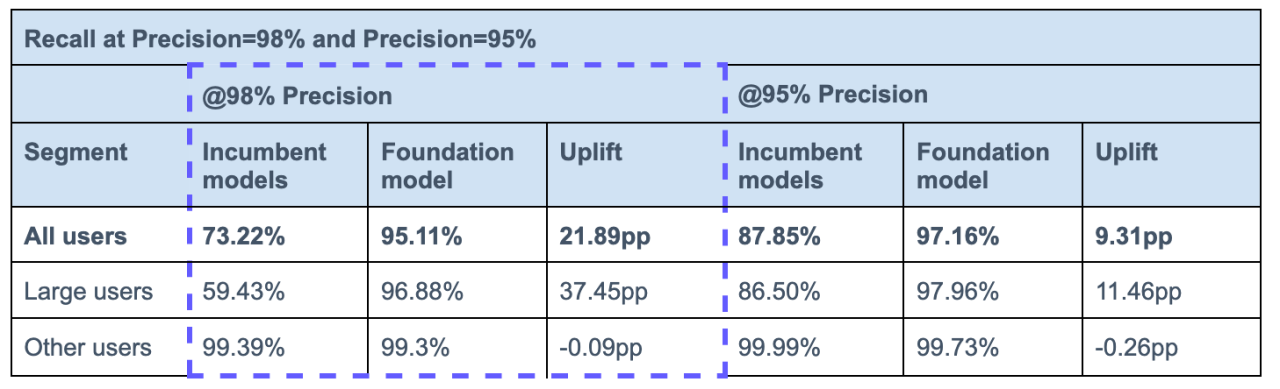
The post went viral.
On Linkedin alone it gained over 5,000 likes, and over 200 comments and reposts each. And if you managed to miss it, pretty much everyone else on Linkedin wrote about it too.
Including myself. And I was a bit more skeptical than the rest.
In my post, I raised a few points that made me think this isn’t as groundbreaking as it seems.
Side note: If you haven’t read it by now, I highly recommend doing so before continuing as it contains relevant context.
Towards the end of my post, I wrote this:

In hindsight, I left this short statement a bit too vague and under-explored. In fact, I believe that this is one of the biggest challenges why LLMs are not going to replace ML models anytime soon.
(And yes, you can quote me on this).
Today I’d like to expand on it and explain why I think that is the case.
Why is score reproducibility important?
Let’s start by defining what I mean by score reproducibility.
It’s actually very simple: When I run the same model multiple times over the same dataset, I expect the results to be identical. Not the high-level performance results, but the actual scores of each event.
They need to remain the same even if I run the experiments at different times or on different machines. The results must remain 100% identical.
Why is that so important? For several reasons:
Firstly, as a general tenet in software engineering, if you cannot reliably reproduce your code results it’s very hard to identify and fix bugs.
Note that it’s not only about detecting bugs, it’s about knowing that you can reliably do so. If you’re unsure why a score changed, that’s a problem.
Secondly, developing models is an iterative process. You run an experiment, analyze the results, introduce a change, run another experiment, and continue repeating the cycle until you’re satisfied.
Not being able to isolate the performance changes of different iterations is a problem.
Yes, you could get the aggregated changes and get a good idea of the overall performance. But if you want to catch more fraud or remove false positives?
You need to look at individual cases and that’s where you’ll get into murky waters.
Why do LLMs struggle with reproducibility?
Here’s both an answer and a demo:
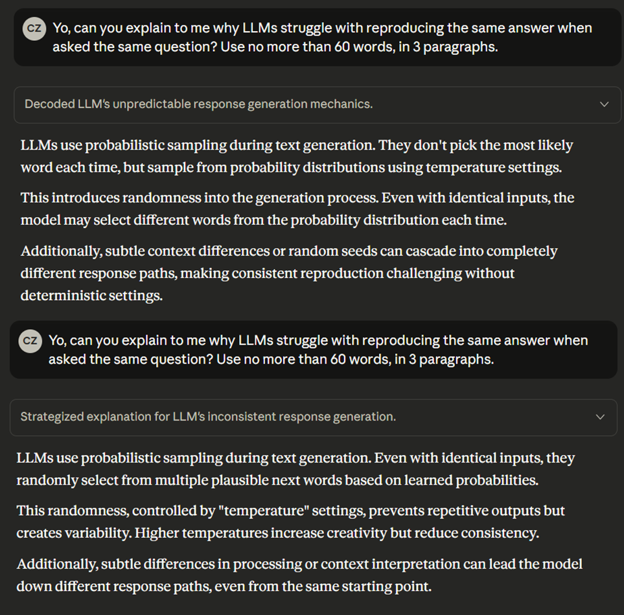
Side note: These are two separate chats.
Now this might not seem like a big discrepancy to you. The two answers are not 100% identical, but semantically they are very similar, right?
True, but:
Scores don’t have semantics. Either it’s the same score or it’s not.
This is a relatively simple question that doesn’t require complex operations like feature extraction or comparing to known samples.
Calculating scores requires mathematical calculations LLMs are known to be bad at.
Scores not only might slightly vary, leading to inconsequential mistakes, but they might be completely different between different runs.
My own experience with using Claude to score transactions showed exactly that.
Are LLMs doomed to fail in scoring?
Long-term, it’s very hard to say and I’m definitely not an expert that can make such predictions.
However, I can say with a very large degree of confidence that this isn’t going to change anytime soon.
That Stripe post? No further explanations were given, no questions were answered, no whitepapers were published.
That data scientist? He recently left the company.
The takeaway?
LLMs seem to be a very convenient solution for many problems. We wish that they could replace ML models because we think they are easier to launch and operate.
But wishful thinking is not a plan, and it’s certainly not evidence.
Those “traditional” ML models? Those are here to stay.
Have you encountered LLM reproducibility issues? How do you manage them without giving up completely on LLMs? Hit the reply button and let me know.
In the meantime, that’s all for this week.
See you next Saturday.
P.S. If you feel like you're running out of time and need some expert advice with getting your fraud strategy on track, here's how I can help you:
Free Discovery Call - Unsure where to start or have a specific need? Schedule a 15-min call with me to assess if and how I can be of value.
Schedule a Discovery Call Now »
Consultation Call - Need expert advice on fraud? Meet with me for a 1-hour consultation call to gain the clarity you need. Guaranteed.
Book a Consultation Call Now »
Fraud Strategy Action Plan - Is your Fintech struggling with balancing fraud prevention and growth? Are you thinking about adding new fraud vendors or even offering your own fraud product? Sign up for this 2-week program to get your tailored, high-ROI fraud strategy action plan so that you know exactly what to do next.
Sign-up Now »
Enjoyed this and want to read more? Sign up to my newsletter to get fresh, practical insights weekly!